How to recover EC2 instances from AZ to AZ using AWS Elastic Disaster Recovery

SHARE THE BLOG
Introduction
Ensuring the flexibility and availability of your critical data and applications is indispensable in today’s fast-paced digital environment. It is in this challenging environment that AWS Elastic Disaster Recovery shines as a beacon of reliability and performance.
When disaster strikes, you don’t just expect immediate recovery — you promise it. AWS gives you the ability to launch recovery instances in minutes, and allows you to restore to the latest state or restore to a specified time, thanks to well-managed backups
But what’s more impressive is the flexibility that AWS offers. Once your applications get back on their feet in the AWS environment, you’re the one calling the shots. You can continue to work in the cloud, take advantage of its scalability and reliability, or, if the time is right, start data replication back to your primary site. It’s a level of control that ensures you’re never stuck in one direction.
AWS Elastic Disaster Recovery (AWS DRS)
AWS Elastic Disaster Recovery (AWS DRS) minimizes downtime and data loss with the fast, reliable recovery of on-premises and cloud-based applications using affordable storage, minimal computing, and point-in-time recovery.
Prerequisites
We suppose the reader has the basic knowledge of AWS(EC2 – EBS – S3), Operation systems, and Networking.
How AWS DRS works
Replication is performed at the block level, via an agent that is installed on each source machine that you want to protect. The agent runs in memory and recognizes write operations to locally attached disks. These writes are captured and then asynchronously replicated into a staging area within the customer’s AWS account. During this ongoing replication process, AWS Elastic Disaster Recovery maintains the write order among all disks in the same source server.
AWS Elastic Disaster Recovery uses Amazon Elastic Block Store (EBS) snapshots to take point-in-time snapshots of this data held within the staging area. It then provides crash-consistent point-in-time recovery options that can be used in the event of a disaster or DR drill.
It is a common misconception that applications, such as MS SQL, Oracle, and SAP Hana, require application-consistent recovery points to recover without corruption. The truth is that most modern applications and file systems can recover from a crash-consistent recovery point since they are ACID-compliant. This means, from a database perspective, that once recovered from a crash-consistent snapshot, any non-completed transactions are rolled back so the database comes up in a consistent state.
Note: A crash-consistent recovery point enables the successful recovery of crash-consistent applications, such as databases. The recovery point will include any data that has been successfully written to the source server volume(s). Application data that is kept in memory is not replicated to the target replication Staging Area until it is written to the source server volume(s). Therefore, if a disruption occurs before in-memory application data is written to the volume(s), this data will not be available on the target server when launched for test or recovery purposes
Understanding Recovery Objectives:
The DRS service provides continuous block-level replication, recovery orchestration, and automated server conversion capabilities. These allow customers to achieve a crash-consistent recovery point objective (RPO) of seconds, and a recovery time objective (RTO) typically ranging between 5–20 minutes. Below is an explanation of how RPO and RTO are measured, how DRS enables these RPOs and RTOs, and what common environment conditions can impact RPO and RTO.
How is Recovery Point Objective (RPO) measured?
RPO is measured based on the latest point in time in which block data was written to the source server volume(s) and successfully copied in a crash-consistent state into the replication Staging Area located in the customer’s target AWS account.
How is Recovery Time Objective (RTO) measured?
RTO is measured from the recovery job start time until the recovered target server is booted and has network access on AWS.
Elastic Disaster Recovery has the following RPOs:
- Every 10 minutes for the last hour
- Once an hour for the last 24 hours
- Once a day for the last 7 days (or a different retention period, as configured)
What environment conditions can impact the ability to achieve a typical RPO of seconds?
To achieve an RPO of seconds, DRS primarily requires that the outbound network, inbound network, and Staging Area resources must allow data to be copied across the network and written to the target environment faster than the rate at which it is written to the source volume(s). In the case that block writes burst at faster rates than these components can support, the RPO will temporarily increase until the data replication can catch up
What environment conditions can impact the ability to achieve a typical RTO of 5–20 minutes?
- OS type: The average recovered Linux server normally boots within 5 minutes, while the average recovered Windows server normally boots within 20 minutes because it is tied to the more resource-intensive Windows boot process.
- OS configuration: The OS configuration and application components it runs can impact the boot time. For example, some servers run heavier workloads and start additional services when booted, which may increase their total boot time.
- Target instance performance: DRS sets a default instance type based on the CPU and RAM provisioned on the source server. Changing to a lower performance instance type will result in a slower boot time than that of a higher performance instance type.
- Target volume performance: Using a lower performance volume type will result in a slower boot time than that of a higher performance volume type with more provisioned IOPS.
AWS DRS Limitations
Elastic Disaster Recovery does not support paravirtualized source servers.
Elastic Disaster Recovery only supports 64-bit operating systems built for the x86 system architecture.
Windows
The following Windows operating systems are supported:
- Microsoft Windows Server 2022 64-bit
- Microsoft Windows Server 2019 64-bit
- Microsoft Windows Server 2016 64-bit
- Microsoft Windows Server 2012 64-bit
- Microsoft Windows Server 2012 64-bit
- Windows10 64-bit
The following End of Life Windows operating systems are supported:
- Microsoft Windows Server 2008 R2 64-bit
- Microsoft Windows Server 2008 64-bit
- Microsoft Windows Server 2003 64-bit
- Windows 7 64- bit
Linux
The following Linux operating systems are supported:
- Amazon Linux (AL) 1 and 2, CentOS 5.6 to 7.0
- Debian Linux 8 to 11
- Oracle Linux (OL) 6.0 to 7.0 (running Unbreakable Enterprise Kernel Release 3 or higher or Red Hat Compatible Kernel only.)
- Red Hat Enterprise Linux (RHEL) 5.0 to 9.0
- Rocky Linux 8
- SuSE Linux Enterprise Server 11 SP4 to 15
- Ubuntu LTS 12.04 to 20.04
Source Server Requirements
General requirements
The following are universal requirements for both Linux and Windows source servers:
- Root directory — Verify that your source server has at least 4 GB of free disk space on the root directory (/) .
- RAM — Verify that your source server has at least 300 MB of free RAM to run the AWS Replication Agent.
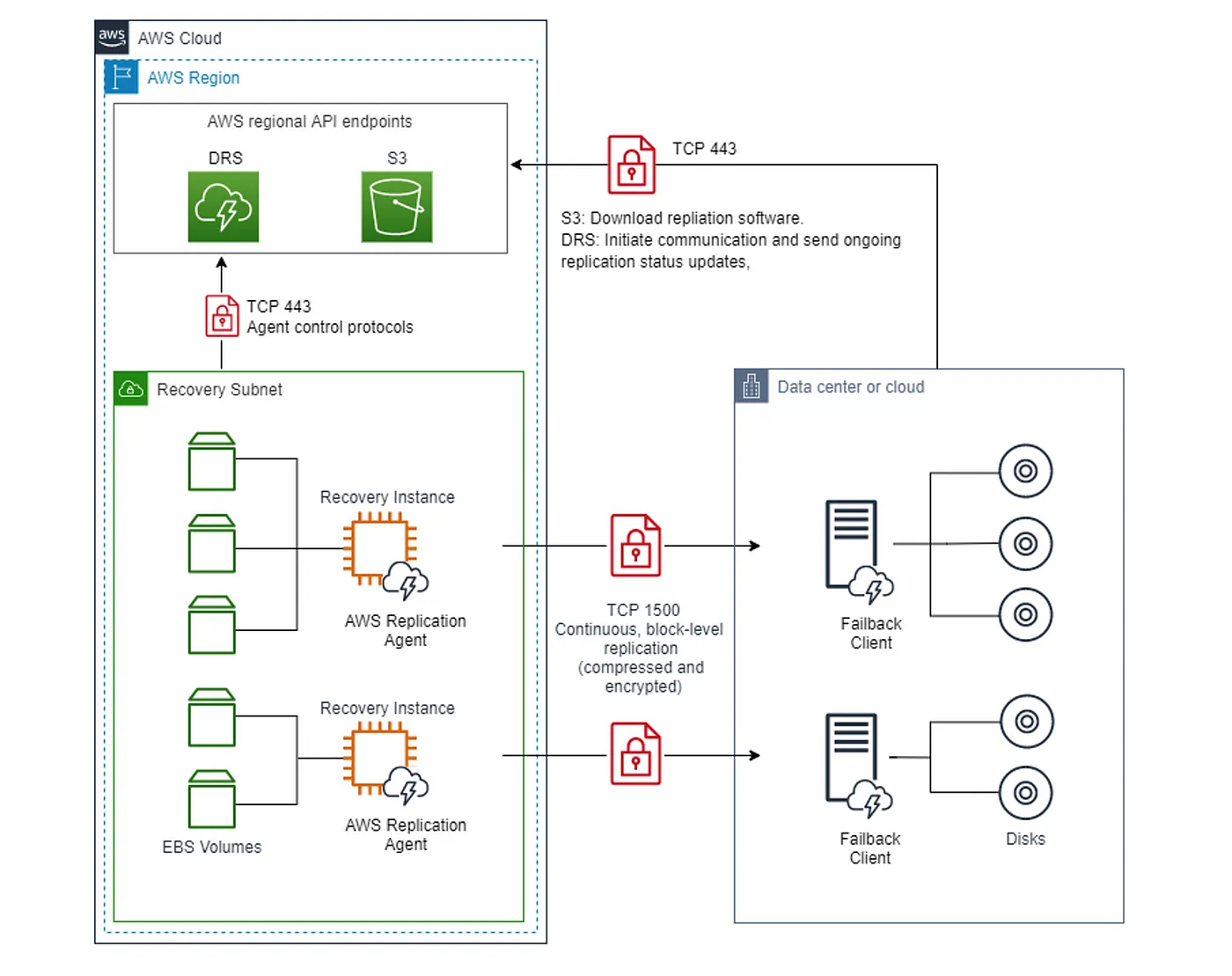
AWS DRS agent network requirements
- Communication over TCP port 443 (detailed here)
- Communication between the source servers and Elastic Disaster Recovery over TCP port 443 (detailed here)
- Communication between the Staging Area Subnet and Elastic Disaster Recovery over TCP port 443 (detailed here)
- Communication between the source servers and the Staging Area Subnet over TCP port 1500 (detailed here)
Solution Implementation.
Step 1: Create two accounts (production account, DR account)
Step 2: Specify us-east-1 as a default region in all our process
Step 3: Create two EC2 in production account (Linux and windows) in (us-east-1b) zone
Step 4: Create two users with programmatic access in an AWS DRS account and download the credential CSV file for each one because it has an access key & secret key that will be used in AWS DRS agent installation.
Step 5: Configure elastic disaster recovery in AWS DRS account
Step 6: Install AWS DRS agent on EC2 (Linux and Windows)
Linux
- wget -O ./aws-replication-installer-init.py AWS Replication Installer
- sudo python3 aws-replication-installer-init.py
Windows
- Download Agent Here
Step 7: Start the sync with the Replication server.
If you face any issues after installing the agent successfully, please check the connection between the agent to EDR on 1500 & 443 outbound
Step 8: Drill source server for testing.
Step 9: Select the Point in time snapshot
Step 10: Check the EC2 dashboard and figure out that linux EC2 has been created in us-east-1f not 1b
Failback to on-premises environment
Failback replication is performed by booting the Failback Client on the source server into which you want to replicate your data from AWS. In order to use the Failback Client you must meet the failback prerequisites and generate failback AWS credentials. The DRS Console lets you track the progress of your failback replication on the Recovery Instances page.
Conclusion.
You can increase IT resilience when you use AWS Elastic Disaster Recovery to replicate on-premises or cloud-based applications running on supported operating systems. Use the AWS Management Console to configure replication and launch settings, monitor data replication, and launch instances for drills or recovery. You can perform non-disruptive tests to confirm that implementation is complete. During normal operations, maintain readiness by monitoring replication and periodically performing non-disruptive recovery and failback drills. AWS Elastic Disaster Recovery automatically converts your servers to boot and runs natively on AWS when you launch instances for drills or recovery.

Mohammad Jomaa